#AI Datasets
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. is using 66 technologies for its website.
Text
Taylor Hebert v3







Taylor in the Trainyard at Night, liminal spaces
Expand for Ai Error, my little rant, and more!

So, fun fact: I've been hard at work creating a sharable embedding for Taylor Hebert (what I picture her looking like, which is a mix of Claudia Black, and about three different awesome women I've known throughout my life)
After 10 hours of failed attempt, I finally got it dialed in, and it was producing fantastic pics of her face in various emotions and poses


So I thought... Awesome! Let's try it in txt2img!!
Aaaaand, then cue this straight -up Hot Garbage:




What. The. Heck.
Went back to SDXL (which cannot train embeddings), and got good images again, but not a reproducible face, body, and expressions.
Okays, so back to the training on SD1. 5:



And TayTay is cute again! Nerdy, pale, a cloud of dark hair. Perfect for Pre-Powers Taylor!
So why the hot mess?
I'll let Taylor express my feelings on the matter:

AAAAAARGH.
But it is now time for all good computery programmery artists to go to bed. Dang. So close!
Tomorrow is back to Chapter Art for The Muddy Princess. Chapter 17 is finished, and just needs it's art accompaniment for the Teaser posting!
Meanwhile: enjoy the Taylor montage!:










#taylor hebert#worm by wildbow#worm fanart#parahumans#fanfiction art#ai tools#ai datasets#sdxl 1.0#SD1.5#stable diffusion#ai artwork#ai art#wtf#why#programming#girls who code
4 notes
·
View notes
Text

Harness the power of AI and machine learning to unlock the full potential of video transcription. Our advanced video transcription services deliver unparalleled accuracy and efficiency, transforming spoken words into text with precision. This innovative solution enhances the performance of your machine learning models, providing high-quality data for better insights and decision-making. Ideal for industries such as media, education, healthcare, and legal, our AI-driven transcription services streamline data processing, saving time and reducing costs. Experience the future of video transcription and elevate your data-driven projects with our cutting-edge technology.
0 notes
Text

Art by Toothy Bj.
15 notes
·
View notes
Text
i want to be in your dataset. put me in your dataset. let me innnnnn
#i love filling out surveys and being part of studies and getting my work included in ai training data#like haha yesss i get to be part of the people who statisticly represent all of my demographic#currently like right this second i'm in a study where i'm representing several thousand people#i'm so powerful and fucking up this dataset spectacularly with my powerfully abnormal behavior lol#anyway hope you all enjoy being represented by me 💪#natalie does textposts
13 notes
·
View notes
Note
Will filing a DCMA takedown mean that the jackass behind the theft will see my legal name and contact info?
I'm not a lawyer so I can't say for sure, but I think it's likely.
For starters, the takedown notice will go to the company so they'll definitely see your details.
nyuuzyou (the person claiming ownership of the dataset into which they've processed all our unlocked works on AO3) has already clearly indicated that they believe they're in the right, and they're willing to fight against the takedown notices - they filed a counter notice to say as much right after OTW filed the first takedown notice with huggingface (the website to which nyuuzyou uploaded the dataset).
They also tried to upload the dataset to two other websites (it's thankfully now been removed).
Given that, it's possible (though I can't judge how likely) that these takedown notices might end up in a court of law somewhere, and in such a case nyuuzyou will definitely have access to them - and all of our IRL names.
This is one of the hazards of DMCA takedown notices, leaving fanwork creators to choose between protecting our creations or connecting our IRL and fannish identities at the risk of doxing. It is also why I've been careful not to say that we must all file takedown notices, in fact I think that anyone who is in a vulnerable situation most emphatically MUST NOT.
Let me be clear.
DO NOT DO THIS IF IT WILL HURT YOU.
Instead, leave that up to fans like myself who have less to lose and are willing to take that risk.
Right now, what we are doing is engaging in both a legal fight but also something of a public awareness campaign.
The huggingface site that is currently hosting this dataset is actually one facet of Hugging Face, Inc. a well known French-American company based in New York City that works in the machine learning space. I can't imagine that they want to be known as bad faith actors who host databases full of stolen material. They are a private company right now, but if their founders ever want to go public (and make a lot of money selling their shares) they would prefer not to be the subject of bad press. I make a note that they might already be preparing for an IPO since their stocks seem to be available for purchase on the NASDAQ private market and they raised $235 million in their series D funding round. This is a company that is potentially valued at $4.5 billion - they have bigger fish to fry than a bunch of members of the public conducting the legal equivalent of a DDoS on them.
Because that's effectively what we're doing - we are snowing them under with takedown notices that have to be individually replied to and dealt with. We are trying to convince huggingface that deleting the dataset nyuuzyou uploaded is the easier and less problematic option than legally defending nyuuzyou's right to post it.
The other thing that we're doing is making a public anti-AI stand.
We are telling the LLM / Gen AI community that AO3 is not the soft target it might look like - they might be able to crawl the site against site rules and community standards but if they post their datasets publicly for street cred (and that's exactly what nyuuzyou is doing) then we will act to protect ourselves.
The status of fanwork as a legally valid creative pursuit - to be protected and cherished like any other - is a long campaign, and one that the OTW was founded on. When @astolat first proposed AO3, it was the next step in a fight that had been ongoing for years.
I'd been a fan for over a decade before AO3 was founded and I personally don't intend to see it fall to this new wave of assaults.
Though it is interesting to be on this end of a takedown notice for once in my life! 🤣
#asks answered#Anonymous#Phlebas blogs her life#fanfic writers on writing#fanfic writer problems#ao3#fanfiction#Generative AI#LLM development#LLM dataset#not mine#and I hate it#Anti AI fightback
11 notes
·
View notes
Note
how much of your writing is ai generated
ngl anon kind of fucking rude to come here and accuse me of that. i don’t make fic just to rack up some arbitrary numbers, be that wordcount or idk, kudos. i make fic because i fucking care about what i’m writing about. if i didn’t, i wouldn’t write it, i certainly wouldn’t post it. AI fic is a plague on fandom for plagiarism reasons, obviously, but also because why should anyone give a shit about your writing if you didn’t? I don’t care if one day we have AI that makes stuff identical in quality to what people can, or better, even, because the words on the page aren’t the point, it’s always about the reason behind putting them down.
So, to answer your question, none of it. And it never will be. I’d rather never write again than stoop to that. And I certainly think less of anyone who does it themselves.
#ask#why would anyone want to read an AI generated fic. just to have more content to consume?#it will never matter it will never say anything because a writing AI has no opinions has no beliefs has no feelings#at most it has biases inherited from the dataset.#an AI can’t explain the choices in a scene to you. or why it picked one word over another. it can spew a bullshit answer if prompted but#that’s not why it made it. it made it because it was algorithmically generating words.#i make shit because it matters to me. the craft is as important as the final product.#if i was reading a fic and the person dumped on me st the last minute that they’d used AI to make it i’d block them. immediately.
24 notes
·
View notes
Text


I tried nightshade and glaze with this painting from 2019!
Protect your images from genAI with Glaze! Paintings, photos, 3D renders... everything! Tell your friends!
32 notes
·
View notes
Text
Death by a thousand cuts in my class this week
#please feel free to ignore this#Jake meets world#I'm going to be really busy the next couple of weeks so I've been working ahead#In (almost) all my other classes every assignment except the exams is available right at the start of the semester#so you could theoretically do the whole thing right away#Not this class#The assignments are locked so you can only start them like 2-3 weeks before they're due#And the assignment I'm working on now is so tedious and confusing#Half of the questions are like 'invent a formula! Now optimize it!'#This is not the invent a formula class this is the AI class#I also just hate having to graph really big datasets because it's such a pain lol#Can't really do it in Excel and trying to do it in Python is like trying to force a mouse to be a rabbit#Also for some reason they have a FAQs document separate from the assignment#so you have to like read the assignment and then read the FAQs to make sure you're doing it correctly#Just put the assignment information in the assignment? Modify the instructions to include this?
6 notes
·
View notes
Text
I'm getting so sick and tired of AI. Someone needs to start mass-feeding it eng dub AG pokemon scripts only or something. Make it watch Spontaneous Combusken 87934573489 times. I think that would sufficiently poison its datasets if we could do it enough times.
#joking of course but seriously I am soooooo tired of AI.#like. from a creator/stealing/etc standpoint yes; but also just in general.#(*generative) AI is only good when it's being used for ridiculous shit. none of this daily life tool stuff.#I miss the 2015 era of AI chatbots.#yall remember chimpbot??? tumblr found it and poisoned its dataset with destiel questions and it just went on about supernatural.#or like. that blog that used to AI generate batshit insane color names like sponk and dingbat green. or the recipe ones#or even those total nonsense AI generated movie scripts like snapcube's sonic script video.#those are funny! that was fun! maybe a little morally dubious still but like at least it produced janky useless fun bullshit only.#can we go back to janky useless fun bullshit?????? please??????
18 notes
·
View notes
Note
Thanks a lot for making this tool, it helps a lot to know exactly which fics were scraped, even if there isn't anything to be done for now. I do want to ask how you managed to grab the data on which fics were scraped? Was it downloaded before the takedown? (This is a purely curious question feel free to ignore)
You're welcome!
It has a whole 11 notes, so I don't think many people SAW it, but I went through how I made the tool right here.
tl;dr: it's based on the metadata-only set someone else linked to on the Hugging Face comments, but I did download the full original dataset as well to confirm with a select few fics.
#unfortunately the full dataset is still available#it's just not on that popular link anymore#so if you really want to dig into the full data it's still possible#i just don't want to be the one to link to it in case someone comes around here looking to actually use it for ai training
4 notes
·
View notes
Note
who/what is the song in your pinned from? i can't stop thinking about it...
i wrote the lyrics and then put them into suno, here is a couple more you might enjoy
2 notes
·
View notes
Text
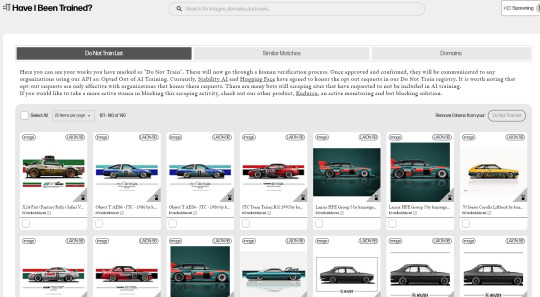
Just a heads up to any non AI artists that use red bubble (among many more). They are allowing your work to be used by the LAION-5B data set for use in AI training. haveibeentrained.com is free to use
9 notes
·
View notes
Text
To be honest I would actually love to see what manner of fucked up art a computer can produce, but the people in charge of the computers insist on pushing them towards flavourless facsimiles of human-made art so companies can use them to cut costs.
#poisoned dataset nonsense ai art > 'realistic' ai images#ai art#ai artwork#organic home grown content
12 notes
·
View notes
Text

Dalla pagina Instagram di dailychatgpt
#chatgpt#dati#dataset#deepseek#proprietà dati#cittadinanza digitale#ai#ia#genai#artificial intelligence#intelligenza artificiale#stolen data
5 notes
·
View notes
Text
my thoughts of the recent case of ai scraping of AO3 is that at least one (1) person within the thousands of fandoms and works that were scraped is rich enough and crazy enough to sue the user who did it. because justice.
#ao3#anti ai#ai#like correct me if i’m wrong but there’s a crazy amount of original works on there#which means it’s literally illegal to sell it to ai#idk bro the user who scraped all these works is gonna experience crazy karma#and right fully so#along with everyone who is using the dataset#may the universe harm them like it does to ao3 writers 🙏
2 notes
·
View notes